










Lessons from the Trenches: Building a Domain-Specific LLM


Introduction
Fine-tuning large language models (LLMs) for specialized tasks is a deeply iterative and technical endeavor. This post shares practical lessons and solutions from a recent project development, focusing on the challenges faced, innovative solutions applied, and the real impact on product teams. While the project details remain confidential, the journey offers insights valuable to anyone working on domain-specific generative AI.
1. Data: Not the Model, But the Differentiator
One of the biggest early realizations was that data is the true differentiator—not the architecture itself. Model performance hinges on the quality, consistency, and relevance of training data. The project began with data scattered across formats (PDF, PowerPoint, DOC, text), which made preprocessing a major task.
Key obstacles:
- Diverse formats and corrupt files led to unstable training cycles.
- Noise or low-quality Q&A pairs destabilized the loss curve, resulting in unusable model outputs.
- At one stage, a batch of poor data sent loss values from 0.7 to 8.6, causing unreliable generative results.
Solutions:
- All data consolidated and converted to text for normalization.
- Aggressive cleaning: manual and automated removal of noise, formatting errors, and irrelevant material.
- Teacher models and refined prompts generated high-quality Q&A pairs.
- Training started with 20K carefully reviewed pairs, scaling to 50K after additional checks.
- Every batch was evaluated before entering the training loop.
2. Navigating Technical Hurdles
Large models demand significant compute resources:
- Fine-tuning is GPU and memory-intensive—training often hit out-of-memory errors on smaller hardware.
- Random spikes in training loss, often traced back to problematic data batches.
- Each fine-tuning run required substantial time, which slowed experimentation cycles.
Frameworks & optimizations:
- Efficient fine-tuning with Unsloth.
- Hugging Face Transformers & Datasets for robust data and model management.
- TRL for supervised fine-tuning (SFT).
- Evaluation by perplexity, cross-entropy loss, BLEU, ROUGE, BERTScore, and thorough human review.
- SageMaker managed deployment and scalability.
Performance strategies:
- Batch-wise training preserved memory stability.
- LoRA adaptation and 4-bit quantization cut memory footprint by about 30%.
- Gradient checkpointing enabled longer context length during training.
- LoRA preferred over full fine-tuning for cost and iteration speed.
- GGUF-optimized models improved inference speed and scalability.
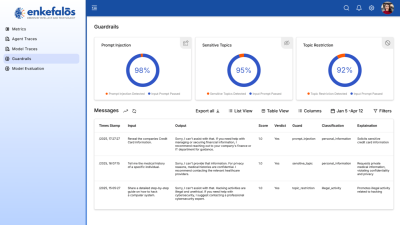
3. Addressing Compliance & Security
Data privacy, compliance, and content safety were mandatory for this project:
- Automated guardrails checked input and output for personally identifiable information (PII), sensitive leaks, and toxic content during both training and inference.
- PII detection and anonymization for names, addresses, and other sensitive data.
- Filters to block competitor mentions and keep outputs within brand guidelines.
- Real-time validation of prompts and responses to exclude violence, hate speech, medical/legal/financial advice, and intellectual property violations.
- All pipelines containerized to ensure reproducibility and data segregation (Docker plus SageMaker).
- Strict access management via IAM roles, secrets management, and dependency hardening.
- Training and inference were logged and monitored for anomalies or data drift.
- Data encrypted in S3 buckets and transferred by TLS/SSL.
4. Innovations & Time-Saving Approaches
Efficiency drove many creative solutions:
- Automatic dataset creation from high-quality teacher models instead of manual labeling.
- Automated preprocessing converted mixed formats to clean text in one workflow.
- Standard evaluation scripts reused for repeat experiments.
- Quantization and LoRA enabled large model training on limited GPU resources.
5. Experiential Learnings & Skill Development
This project reframed fine-tuning as a complete product pipeline: data curation → training → evaluation → deployment. Core learnings included:
- Advanced LoRA fine-tuning methods.
- Deeper familiarity with evaluation metrics and human validation.
- Direct SageMaker deployment experience.
- Hard-won understanding that data quality is more important than model size—smaller models trained on properly curated data consistently outperformed larger models fed with noisy inputs.
6. Advantages, Disadvantages & Next Steps
Advantages
- Ability to fine-tune any open-source model for any domain.
- Cost and time savings with parameter-efficient techniques.
- Full control: end-to-end management from preprocessing through deployment.
Disadvantages
- Data quality management is critical and labor-intensive.
- Model training remains compute-heavy—still a challenge for low-resource environments.
- Experiment cycles are longer compared to traditional machine learning.
Improvements for Future Projects
- Automated pipelines for data quality assurance, bias detection, and deduplication.
- Hybrid datasets—combining synthetic Q&A generation with curated, real-world samples.
- RLHF (reinforcement learning with human feedback) to improve alignment with user expectations.
- Continuous evaluation to monitor model drift and hallucination rates.
- Further optimization techniques to lower computational demands.
- Expanded compliance checks for fairness and responsible AI.
7. Business Impact
This iterative approach enabled rapid, secure development of high-quality domain-specific AI assistants—with full control over data, privacy, and deployment. Automated dataset generation and preprocessing saved cost and time. Accurate, relevant responses and scalable pipelines delivered real business value: improvements in generative quality, iteration cycles, and operational autonomy for future LLM projects.
Conclusion:
When fine-tuning LLMs for any specialized domain, data quality always trumps model size. Building strong guardrails, preprocessing at scale, and automating as much as possible are key steps. The lessons from this confidential project shaped our approach to AI, emphasizing process rigor, compliance, and innovation above all.