










How to Evaluate, Monitor, and Tune Your LLMs: From Hallucination Control to RLHF


In the earlier articles of this series, we explored why enterprises should own their Large Language Models (LLMs), how vertical GenAI is transforming industries, and how platforms like GenAI Foundry make it possible. We also demonstrated real-world adoption through InsurancGPT.
Now comes the next critical question:
“Once you own your model, how do you ensure it stays accurate, safe, compliant, and continuously improving?”
This article addresses that challenge — showing why evaluation, monitoring, and reinforcement tuning are the backbone of Responsible AI.
1. Why Model Evaluation Matters
Owning your model is only the first step. Without evaluation, an enterprise risks:
- Hallucinations: Models generating plausible but false outputs.
- Bias: Hidden tendencies that skew outputs against certain groups or policies.
- Compliance breaches: Outputs that violate regulations (GDPR, HIPAA, NAIC).
- Performance drift: Models that become less accurate as real-world data evolves.
In regulated industries, even small deviations can cost millions.
Imagine an underwriting model that misclassifies risk by 5% — this could mean approving high-risk policies without adequate pricing, leading to catastrophic loss ratios.
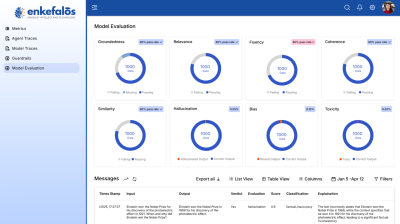
2. Multi-Layered Evaluation Approach
Robust evaluation combines automatic benchmarks, human oversight, and domain-specific rules:
- Automated Metrics
- Perplexity: How well the model predicts language.
- BLEU, ROUGE, Meteor: Translation/summarization quality.
- BERT Score: Semantic similarity.
Fast signals that indicate whether fine-tuning is working.
- Domain-Specific Benchmarks
- Insurance: ACORD compliance claims classification accuracy.
- Healthcare: ICD-10 coding precision, medical QA benchmarks.
- Finance: Named-entity recognition for transactions.
These tailor evaluation to the industry’s “language of truth.”
- LLM-as-a-Judge
Pairwise comparison using stronger models to score reasoning.
Example: Using a reasoning model to evaluate whether outputs align with compliance rules. - Human-in-the-Loop (HITL)
Regulators and executives expect a “human safeguard.”
With HITL checkpoints, experts review outputs flagged as high-risk before they flow into production systems.
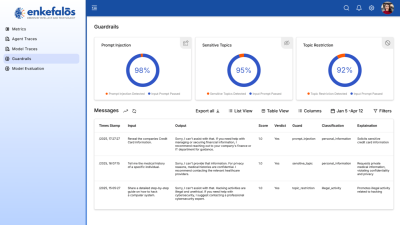
3. Guardrails & Safety
Evaluation alone is not enough — enterprises need real-time defenses.
Guardrails ensure AI never crosses compliance or ethical boundaries:
- Prompt Injection Defense: Block attempts to manipulate models into unsafe outputs.
- Restricted Topics: Forbid responses on sensitive or off-policy areas.
- Business Rule Validation: Validate extracted or generated data against structured rules (metadata-driven).
- Auditability: Logs of every interaction, with explainability for regulators.
Think of guardrails as the airbags and seatbelts of AI. They don’t stop the car from moving fast — they make it safe to drive.
4. Continuous Improvement with RLHF & DPO
Owning a model means you’re not stuck with static performance. You can continuously improve:
- RLHF (Reinforcement Learning from Human Feedback)
- Collects feedback from users on whether outputs were useful, accurate, or compliant.
- Feeds this into retraining to align the model closer to enterprise expectations.
- DPO (Direct Preference Optimization)
- Scales preference alignment without expensive reinforcement setups.
- Enables faster adoption of user preferences into production models.
- Guardian Loops
A “feedback → retrain → redeploy” cycle, ensuring the model evolves with business needs and regulatory changes.
This transforms an LLM from a static tool into a living enterprise asset.
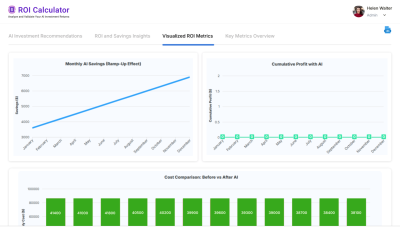
5. Observability & Monitoring
Evaluation isn’t just one-time. Enterprises need continuous observability to maintain trust.
Dashboards track:
- Hallucination rate (e.g., % of invalid claims extractions).
- Bias scores (ensuring no skew across gender, geography, or customer type).
- Accuracy drift over time.
- Latency and throughput for production-grade SLAs.
Alerts notify leadership when KPIs cross thresholds.
For example: “Hallucination rate > 3% in underwriting extraction this week” → triggers retraining or HITL escalation.
6. The Business Impact
Why should decision-makers care? Because strong evaluation and monitoring:
- Reduces compliance risk → avoids regulatory fines and reputational damage.
- Builds trust with executives and regulators → auditable AI earns faster adoption.
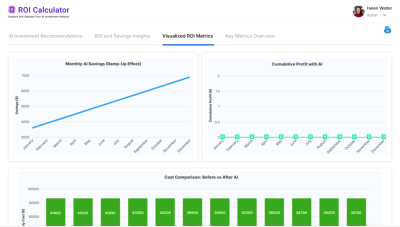
- Improves ROI → models aligned with enterprise data are more accurate, lowering error costs.
- Creates IP moat → a continuously improving, domain-tuned model is a defensible asset.
7. Putting It All Together
With GenAI Foundry, enterprises get this out-of-the-box:
- Low-code pipelines for fine-tuning → evaluation → deployment.
- Built-in guardrails for safety and compliance.
- RLHF/DPO integration for continuous learning.
- Monitoring dashboards to keep leadership informed.
It’s not just about building a model.
It’s about running it responsibly, continuously improving it, and proving compliance at every step.
🔜 Next in Series →
In the next article, we’ll launch Fine-Tune Fridays: weekly updates where we share evaluation results from vertical models we’re training (Insurance, Finance, Legal, Healthcare). This will showcase real-world performance and keep the research conversation alive.
This is part of our series “From API Dependence to AI Ownership”, where we explore how enterprises can secure, own, and scale GenAI responsibly.