











Enkefalos Research
At Enkefalos Technologies, we believe in research that translates into real impact.
Modern AI systems, especially Large Language Models (LLMs), are powerful—but still fundamentally flawed when it comes to reasoning, perspective, and reliability in real-world scenarios. Our research team is focused on going beyond token prediction to build AI that understands, reasons, and aligns with human cognition.
We publish whitepapers not as academic vanity - but as a bridge between deep technical exploration and applied enterprise solutions. Our innovations, from Theory-of-Mind (ToM) reasoning to domain-specific architectures like InsurancGPT, directly inform our commercial deployments.
We thank our research partner MQube Cognition for contributing significantly to this mission.
Why Research at Enkefalos?
We do research to solve problems that matter in the real world:

- Our clients operate in regulated, high-risk industries (insurance, finance, public safety).
- These domains need trustworthy AI that can reason, infer, and adapt—not just autocomplete.
- Generic LLMs are fragile and verbose. We’re fixing that by pushing the limits of model reasoning.
- Each paper informs a product—whether it’s our InsurancGPT copilot, our custom GenAI solutions, or low-resource language models.
Our Whitepapers
Each whitepaper below is a snapshot of our research journey, solving one core weakness in current AI systems.
Impact of Noise on LLM-Models Performance in Abstraction and Reasoning Corpus (ARC) Tasks with Model Temperature Considerations
- What’s the problem? Models like GPT-4o fail when even tiny noise is introduced into abstract reasoning tasks.
- What we did: Used the ARC benchmark and systematically injected noise (0.05–0.3%) into grids to test model resilience.
- Key Result: GPT-4o collapsed under minimal noise. LLaMA and DeepSeek failed even in noiseless conditions.
- Use case: We now build noise-aware abstraction engines in AI copilots.

Exploring Next Token Prediction in Theory of Mind (ToM) Tasks: Comparative Experiments with GPT-2 and LLaMA-2 AI Models
- What’s the problem? LLMs lose grounding when you increase distractors in narrative tasks, failing to infer intent.
- What we did: Inserted 0 to 64 distractor sentences in Theory-of-Mind stories and tracked token prediction.
- Key Result: Both GPT-2 and LLaMA-2 showed significant performance degradation. LLaMA-2 resisted better but still struggled with nested beliefs.
- Use case: We are designing intent-tracking models that maintain coherence under ambiguity.

Representational Alignment in Theory of Mind
- What’s the problem? Most models don’t organize internal knowledge by belief or perspective—they cluster by keywords.
- What we did: Conducted triplet-based alignment tasks and evaluated similarity matrices.
- Key Result: Alignment improved ToM reasoning accuracy. Our work was featured at the ICLR 2025 Re-Align Workshop.
- Use case: This research powers our belief-aware reasoning layers in copilots.

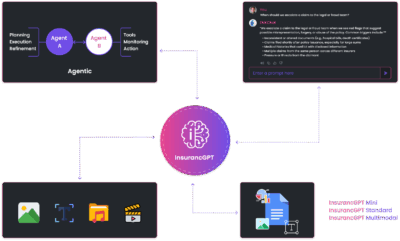
InsurancGPT: Secure and Cost-Effective LLMs for the Insurance Industry
- What’s the problem? General LLMs don’t perform well on industry-specific tasks like claims, underwriting, or policy compliance.
- What we did: Built InsuranceGPT, a fine-tuned Mistral-based model trained on NAIC, CPCU, and claims data.
- Architecture: Combines Direct Preference Optimization (DPO) with Retrieval-Augmented Generation (RAG).
- Key Result: Outperformed GPT-4 and GPT-3.5 in BLEU, METEOR, and BERTScore on insurance tasks.
- Use case: Now deployed in production copilots across document intelligence, policy QA, and fraud detection.

What’s Next?
We’re expanding research in the following areas:
- Foundational Large Language models for native languages (e.g., NammaKannadaGPT)
A Fully Native Kannada AI Model (One of the premier regional languages in India)
Foundational Large Language Model (LLM) for Kannada, developed from scratch. This ensures true native-language understanding and generation, making AI more accessible for Kannada speakers.
HuggingFace link
- Multimodal reasoning agents for strategy, pricing, and compliance
- Granular error monitoring and explainability (SHAP, HITL, adaptive retraining)
We welcome collaboration with researchers, insurers, and product teams who believe in applied, explainable, and resilient AI.