Blog
From AI Pilot to Production: The governance framework every enterprise needs


Most enterprises no longer struggle to build AI pilots. They struggle to operationalize them. The challenge is not model performance. It is governance, accountability, and operational control.
Whether organizations can run AI in production with predictable value, operational control, and evidence that leaders, auditors, and customers can trust. That gap is real. McKinsey’s 2025 global survey found that 88 percent of organizations use AI in at least one business function, yet most remain in experimentation or pilot stages, and only about one-third say they are scaling AI across the enterprise. BCG similarly found that only 26 percent of companies have built the capabilities needed to move beyond proofs of concept and generate tangible value.
From the Enkefalos Tech perspective, the answer is not more disconnected pilots. It is a governed execution. We describe enterprise AI as a control problem as much as a model problem, emphasizing ROI-gated deployment, data readiness, runtime governance, continuous evaluation, controlled learning with human oversight, and ownership of data, models, and IP inside the customer’s own environment.
Understanding the AI Production Gap
Why AI Pilots Succeed but Production Deployments Fail:
AI pilots usually succeed because the conditions are forgiving. Teams work with curated datasets, limited user groups, narrow workflows, and generous room for manual intervention when something goes wrong. Production AI, by contrast, must survive live integrations, changing data distributions, privacy and access controls, uptime expectations, rollback requirements, and downstream business consequences. Google’s ML engineering guidance is blunt on this point: start by making the pipeline work end to end and keep the early system simple. Google’s technical-debt research reaches the same conclusion from a different angle, showing that ML systems quickly accumulate hidden dependencies, feedback loops, and “pipeline jungles” that make them difficult and expensive to maintain over time.
The implication is important for any enterprise moving from AI pilot to production. A model can be accurate in an offline test and still be unfit for real operations. Google’s ML Test Score paper argues that production readiness depends on testing and monitoring, because training data needs testing like code and trained models need production practices such as debuggability, rollback, and monitoring. In other words, the model is only one part of the system that must be production ready.
The Hidden Governance Gap in Enterprise AI:
Most failed deployments are described as data problems or model problems, but the deeper issue is governance. NIST organizes AI risk management around four functions: GOVERN, MAP, MEASURE, and MANAGE and explicitly calls for documented roles, executive accountability, human oversight, ongoing risk tracking, incident identification, and the ability to disengage systems that produce outcomes inconsistent with intended use. Enkefalos echoes that operating philosophy in enterprise terms, positioning production AI as a governed control layer with continuous evaluation, runtime guardrails, and auditability built in by default rather than added later as documentation.
This table is a shift from experimentation to managed operations, where AI becomes part of enterprise risk, controls, and accountability.

Building the Foundation for Production-Ready AI
The foundation of production-ready AI starts before deployment. Our published operating model stresses economic validation, data foundation readiness, responsible AI, continuous evaluation, and controlled learning. That is a useful lens because enterprises often try to operationalize AI too late, after a pilot has already created stakeholder expectations. A stronger approach is to design governance into the system from the start.
Operational Control Requirements for Production AI. A workable enterprise governance framework should include five control layers:
- Executive ownership and clear decision rights: NIST requires documented roles, lines of communication, and executive responsibility for AI risk decisions across development and deployment.
- Data readiness, lineage, and privacy controls: Google’s production-readiness rubric calls for feature schemas and privacy controls across the data pipeline, while Enkefalos emphasizes private deployment, so data and workflows stay inside the customer’s environment.
- Structured testing, evaluation, validation, and verification: NIST’s Generative AI Profile highlights robust pre-deployment TEVV, and Google’s ML Test Score provides 28 practical tests to assess whether a system is truly ready for production.
- Controlled release management: Google’s MLOps guidance shows that mature setups move from manual model deployment to automated pipelines with validation, metadata management, source control, model registry, and CI/CD routines.
- Human oversight, guardrails, and safe fallback: NIST calls for defined human oversight and the ability to supersede or deactivate systems that behave outside intended use; Enkefalos translates that into runtime safety, governed learning, and controlled releases.
Compliance and Auditability in Enterprise AI:
Compliance is not a policy of PDF sitting in a shared folder. It is the ability to prove how the system was built, what data it used, how it was tested, who approved it, what it did in production, and what happened when it failed. The EU AI Act is a strong reference point here because it requires risk mitigation, high-quality datasets, logging for traceability, technical documentation, deployer information, human oversight, and robust, secure operation for high-risk systems. NIST’s Generative AI Profile adds practical expectations around document retention for testing and validation history, incident response, incident disclosure, and post-deployment monitoring.
|
Control objective |
Evidence enterprises should retain |
|
Data governance |
Data source lineage, schema expectations, access controls, validation results |
| Model governance |
Model version, evaluation results, approval records, rollback path |
|
Runtime governance |
Input and output logs, drift alerts, incidents, override actions |
| Compliance governance |
Technical documentation, instructions for use, audit history, retention records |
The exact artifacts will vary by industry, but the principle does not: if a decision affects customers, employees, risk, or regulated workflows, enterprises need evidence that is generated as part of normal operations, not assembled after an incident.
Monitoring and Observability for AI at Scale
The clearest dividing line between a launch and real AI in production is monitoring. Google’s MLOps guidance treats monitoring as a core stage in the production lifecycle and explicitly links it to retraining and new experiment cycles. Official model-monitoring documentation from Google Cloud and AWS focuses on the practical signals that matter in production: input drift, output drift, training-serving skew, feature attribution drift, data quality, model quality, and bias drift. NIST goes further by recommending post-deployment monitoring that also captures user feedback, appeals, overrides, incident response, recovery, and change management.
A practical monitoring baseline should include:
- Input quality and schema drift, so teams know when live data stops looking like training data.
- Output quality and business performance, including accuracy, failure patterns, and downstream impact where labels exist.
- Bias, safety, and feature attribution changes, especially when model outputs influence human decisions.
- Operational health, including latency, uptime, cost, retraining triggers, rollback events, and incident response performance.
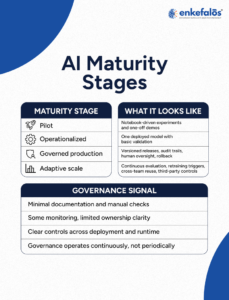
The Production AI Maturity Model
A practical maturity model, synthesized from Google’s MLOps levels, NIST’s lifecycle controls, and Enkefalos’s control-plane approach, looks like this:
Key Questions Enterprise Leaders Should Ask Before Scaling AI:
Before expanding any deployment, leaders should be able to answer a short list of questions with evidence rather than intuition:
- What business outcome does this system own, and how is value measured?
- What data sources, model versions, and prompts or policies are currently in production?
- What human approvals, override paths, and shutdown criteria exist?
- What gets logged, retained, and reviewed after incidents or model changes?
- What signals trigger retraining, rollback, or decommissioning?
- Which third-party models, APIs, or datasets are inside the value chain?
If those answers are incomplete, undocumented, or dependent on a few people’s memory, the organization is still operating like a pilot, even if the model is technically live. That is exactly why NIST places so much emphasis on documented roles, measurement, incident processes, and regular monitoring over the full lifecycle.
Conclusion
Moving from AI pilot to production is not a model handoff. It is an operating model decision. Enterprises need governance that combines executive accountability, data controls, structured testing, release discipline, runtime guardrails, continuous monitoring, and auditable evidence. Enkefalos Tech’s own position is clear: production AI should be private by design, governed by default, and continuously evaluated with human oversight, especially in regulated environments where trust, traceability, and control matter as much as raw model performance. That is the standard enterprises should use when they decide whether an AI system is truly ready for production.
FAQ
1. What is an AI governance framework?
An AI governance framework is the set of rules, responsibilities and checks that tells an organization how AI should be used safely. It covers the full journey of an AI system, from the data it is trained on to the way it is deployed, monitored and reviewed after launch. It also defines who is accountable for AI decisions, how risks are managed, and how compliance requirements are enforced.
2. What does production-ready AI mean?
Production-ready AI means an AI system is ready to work in a real business environment, not just in a test or pilot setting. It has been checked for accuracy, security, reliability, scalability, and compliance before being used in live workflows. Production-ready AI includes more than the model itself. It requires approved data sources, deployment controls, version history, human review processes, audit logs, rollback options, monitoring capabilities, and measurable business outcomes.
3. Why do most enterprise AI projects fail after the pilot stage?
Most enterprise AI projects fail after the pilot stage because pilots prove possibility, not operating readiness. BCG reports that only 26 percent of companies have the capabilities to move beyond proof of concept and create tangible value, while McKinsey shows that most organizations still remain in pilot phases and IBM reports only 16 percent of AI initiatives have scaled enterprise wide.
4. What is the biggest difference between an AI pilot and a production-ready AI system?
The real difference shows up after launch. In a pilot, things are still controlled. The data is limited, teams can step in manually, and mistakes are easier to catch. But once AI goes into production, it has to work reliably in live business conditions. That means the system needs owners, tested data flows, release controls, monitoring, rollback options, human checks, and a clear record of what changed and when.
5. What are the essential components of an enterprise AI governance framework?
An enterprise AI governance framework should make three things clear: who is responsible, what risks exist, and how the system is controlled. That usually includes leadership accountability, risk mapping, data governance, model testing, deployment approvals, human oversight, logging, documentation, monitoring, incident handling, and checks on any third-party models or data sources.
6. How can organizations ensure AI models remain accurate and reliable over time?
Organizations should continuously monitor live inputs and outputs, compare training and serve behavior, detect drift, review user feedback and incidents, validate retraining before release, and maintain rollback or deactivation procedures when performance moves outside defined limits. That is how AI stays reliable after launch rather than degrading silently in production.
7. What risks do enterprises face when deploying AI without proper governance?
Without governance, the problem is not just that an AI system may give a wrong answer. The bigger problem is that the organization may not know how that answer was produced, who approved the system, or how to fix it when something goes wrong. That can lead to biased or inaccurate outputs, privacy gaps, security issues, compliance problems, and models that keep running even after their performance has dropped.