











Evaluating Large Language Models

Welcome to the first article in our three-part series titled “Evaluating Large Language Models”.
In this inaugural article, we embark on a journey to explore the evolution and significance of benchmarking intelligence, with a special focus on Large Language Models (LLMs). We delve into the history of intelligence benchmarks and how these metrics have been adapted to assess the capabilities and performance of LLMs. This series aims to shed light on the multifaceted approach to evaluating these sophisticated models, from established benchmarks to innovative evaluation methods.
In our subsequent articles, we will dive deeper into the most recognized benchmarks in the field, providing detailed analyses and examples. The final article will cover various evaluation methods, including both quantitative metrics like Exact Match (EM), F1 score, and Expected Calibration Error (ECE), as well as qualitative considerations such as fairness and robustness. We will also explore the role of human evaluation and the potential of using GPT-4 itself as a judge. Stay with us as we navigate through the intricate landscape of Large Language Model evaluation.
Introduction to Machine Intelligence Evaluation
When we consider intelligence, human intelligence naturally is the first option for our benchmark, requiring diverse methods for measurement and evaluation. The understanding of human intelligence contains numerous approaches, including IQ tests and cognitive games. Throughout history, our continuous efforts have been towards comprehending, assessing, and pushing toward the boundaries of various facets of human intelligence. However, with the new information age, a new dimension of human intelligence is emerging, sparking interest in both academia and industry, machine intelligence, in the field of Natural Language Processing (NLP) termed as Language models. These language models are typically formulated with Deep Neural Networks (DNNs) that possess incredible language comprehension and generation capabilities. This leads to the question of how to measure and assess the level of this type of intelligence.
Evolution of NLP Benchmarks
In the earlier stages of NLP, researchers have considered straightforward benchmark tests to evaluate their language model. In the late 1900s, MUC evaluation primarily relates to information extraction texts, challenging systems to extract specific information from text. With the rise of DNNs in the 2010s, the NLP community evolved with more expansive benchmarks like SNLI, and SQUAD . With the rise of large-scale pre-trained models, namely BERT, GPT based models, evaluation methods needed to adapt to assess the performance of these new types of generated models. This led to the rise of the following benchmarks for evaluation, including but not limited to; XNLI, CoNLL, SemEval, GLUE, and SuperGLUE. These benchmarks fostered continuous refinement in NLP evaluation methods, to compare the capabilities of these diverse systems.
With the rise of expansion of the size of language models, large language models (LLMs) have gained incredible traction and noteworthy performance on any given task, under both zero and few shot settings, rivaling again fine-tuned pre-trained models. This led to a landscape of evaluation benchmarks to evaluate knowledge, reasoning, truthfulness, and various other capabilities of these systems. The rapid adoption of ChatGPT , where 100 million users were able to experiment in just 2 months. This sudden growth lead to the use of LLMs in various tasks including text generation, code generation, and question answering systems. However, with their rise, also led to further questions about the potential risks of deploying these LLMs at scale without thorough and comprehensive evaluation. Critical issues such as perpetuating bias, spreading misinformation, and compromising privacy data, need to be addressed. In response to this, led to the line of research with a focus on empirically evaluating the extent to which LLMs align with human preferences and values. While previously mentioned evaluations have focused predominantly on the capabilities of the systems, the new research aims to steer the advancement and capabilities of LLMs in a way that maximizes their benefits by also proactively mitigating risks.

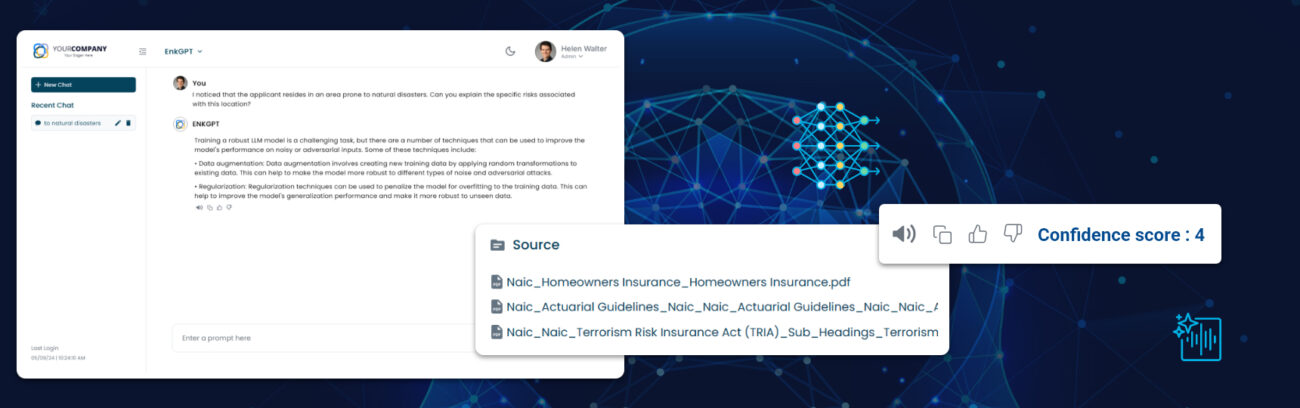
Picture title: Major categories and subcategories of LLM evaluationRef of image
Source : (https://arxiv.org/pdf/2310.19736.pdf)
Evaluating LLMs: Benchmarks and Challenges
While numerous benchmarks have been developed to evaluate LLM’s capabilities and alignment with human values, they often compare performance on singular tasks (sentence analysis, text generation..) or specific domains. It is of utmost importance to evaluate LLMs for their success due to several factors.
- First, assessing LLMs allows for a deeper understanding of their strengths and limitations. For example, PromptBench has revealed that LLMs are vulnerable to adversarial prompts [reference], indicating the necessity of refined prompts for improved performance.
- Second, improved evaluations can offer guidance for interactions between LLMs and humans.
- Third, given LLM’s capability of a wide range of applications, it is crucial to ensure their safety and reliability, especially where safety is paramount, like finance and healthcare.
- Lastly, due to their continuously evolving in size and developing new capabilities, current evaluation methods may not sufficiently assess their abilities and associated risks.
Overview of Popular LLM Benchmarks
Table gives an overview of the open sourced popular benchmarks that are available to evaluate, depending on focus and different domains.
| Benchmark | Focus | Domain | Evaluation Criteria |
| CUAD | Legal contract review | General language task | Legal contract understanding |
| MMLU | Text models | Genrate langage task | Multitask accuracy |
| TRUSTGPT | Ethics | Specific down stream task | Toxicity, bias and value – alignment |
| OpenLLM | Chatbots | General language task | Leaderboard ranking |
| Chatbot arena | Chat assistants | General language task | Crowdsourcing and Elo rating system |
| Alpaca Eval | Automated Evaluation | General language task | Metrics, robustness and diversity |
| ToolBench | Software tools | Specific downstream tasks | Exexcution success rate |
| FreshQA | Dynamic QA | Spe | Correctness and hallucination |
| PromptBench | Adversiral prompt resilience | General Language task | Adversarial robustness |
| MT-Bench | Multi turn conversation | General language task | Winrate judged by GPT-4 |
| LLMEval | LLM Evaluator | Genral language task | Acc, macro-f1 and kappa correlation coefficient |
Summary
In this article, we looked at the history of benchmarking intelligence in general, pivoting towards benchmarks in LLMs. In the next article, we will look at the popular benchmarks as illustrated in the table in detail with a few examples. In the third article, we will look at different methods to evaluate (hint: Automatic evaluation using Exact Match (EM), F1 score, confidence level metrics such as Expected Calibration Error (ECE), Area Under the Curve of selective accuracy and coverage (AUC) and finally qualitative metrics such as fairness, robustness. Other methods also include human evaluation or GPT-4 as a judge)
Referred papers:
- A Survey on Evaluation of Large Language Models [https://arxiv.org/pdf/2307.03109.pdf]
- PromptBench: [https://arxiv.org/pdf/2312.07910v1.pdf]
- TRUSTWORTHY LLMS: A SURVEY AND GUIDELINE FOR EVALUATING LARGE LANGUAGE MODELS’ ALIGNMENT [https://arxiv.org/pdf/2308.05374.pdf]
- Evaluating Large Language Models: A Comprehensive Survey [https://arxiv.org/pdf/2310.19736.pdf]