The enterprise GenAI platform for full control over your model, data, and intelligence — tailored for regulated industries.
Purpose-built intelligence for insurance workflows with auditability, explainability, and regulatory controls.
High-quality Kannada language models for governance, search, and conversational AI.
Stay current with GenAI trends, platform updates, research insights, and practical perspectives on deploying AI in regulated environments.
Subscribe to newsletters and curated articles for the latest updates and expert takes.
Real-world outcomes from deployments—how we helped organizations achieve measurable results.
Enterprise-grade GenAI platforms built for regulated environments—control, auditability, outcomes.
A decade of global experience leading digital transformation and delivering impact.
Principles that guide how we build, partner, and deliver trusted AI at scale.
A private AI execution platform for enterprises operating in regulated environments.
Your Data, Your Model, Your IP
No vendor lock-in. No black boxes. No irreversible decisions.
AI should earn its way into production.
Every initiative is evaluated against economic impact, risk-adjusted ROI, and payback discipline before it ships. If value cannot be defended, it does not deploy.
AI is only as defensible as the data behind it.
We assess completeness, bias, regulatory sensitivity, and traceability before data is used by models. This prevents scale failures and audit risk downstream.
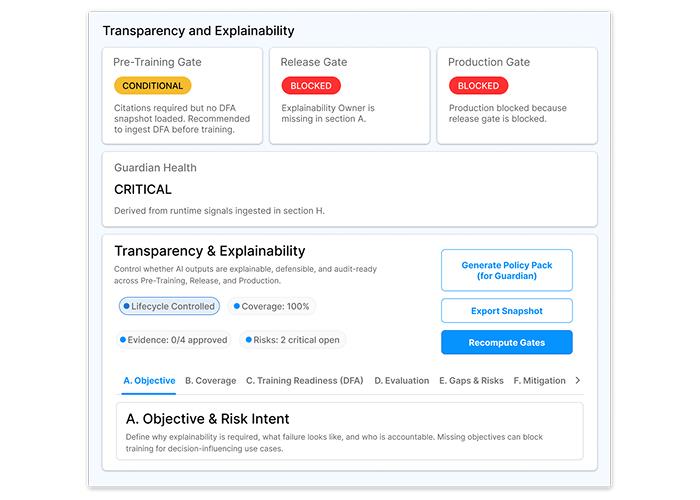
Governance is enforced, not documented.
Accountability, transparency, privacy, safety, and compliance are built into runtime decisions with evidence captured by default. Responsible AI operates as a control system, not a policy statement.
AI systems are monitored continuously in production.
Performance, drift, bias, and risk signals are measured against defined thresholds with full traceability.
Every output remains observable and auditable over time.
AI learns only with human oversight.
Feedback, approvals, and reinforcement signals are governed through structured human-in-the-loop workflows. Learning improves accuracy without introducing uncontrolled behavior.
Performance, drift, bias, and risk signals are measured against defined thresholds with full traceability. Every output remains observable and auditable over time.
Enkefalos operates as a control layer across the AI life cycle. Every decision is measurable Every output is traceable.
1
AI must survive economic scrutiny before it ships.
2
Access and prepare enterprise data for AI workloads.
3
Decision rights, audits and oversight by design.
4
Domain-trained models in core processes.
5
Every output is traceable and defensible.
Private AI control plane for regulated enterprises. Build, govern, and release AI safely across domains and use cases.
Own your models. Own your data. Own your intelligence.
Purpose-built AI models created and managed through GenAI Foundry.
Domain models inherit governance, safety, and control from the Foundry while remaining fully configurable.
Domain Specific Models
Foundation Model
Secure
InsurancGPT is a private, insurance-native AI platform that supports underwriting, claims, documents, and compliance by embedding AI directly into existing insurance workflows.
Insurance-specific reasoning for underwriting, claims, policy, and compliance
Evidence-backed responses with traceability to source data
Governed learning and approvals via Foundry controls
Deployed in regulated environments with full auditability
Enkefalos combines applied AI research with production discipline - evaluation systems, governed improvement, and lifecycle control - so enterprise AI remains explainable, auditable, and defensible over time.
Evaluation systems
Regression testing and quality baselines that prevent silent degradation.
Controlled improvement
Fine-tuning and RLHF as governed operations - versioned and reviewable.
Accountability by design
Decision rights, audit evidence, and monitoring embedded in the system.
AI embedded into an insurance platform reduced quote comparison time by 60–70%, operational queries from minutes to seconds, and policy document review time by 75–85%, while continuously learning user preferences and decisions.
Large-scale production AI implementation for high-volume logistics and supply chain optimization.
We meet ISO 27001, SOC 2 Type 2, HIPAA and CCPA compliance requirements, ensuring your data is protected with enterprise-grade security.
We align technology, governance, and economics to deliver value that holds up under scrutiny.